

基于Spark的电影推荐系统 详见 http://www.php3.cn/a/180.html
1、简介
Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。经典算法包括协同过滤、聚类、分类等等。
Taste 是 Apache Mahout 提供的一个协同过滤算法的高效实现,它是一个基于 Java 实现的可扩展的,高效的推荐引擎。Taste 既实现了最基本的基于用户的和基于物品的协同推荐算法,同时也提供了扩展接口,使用户可以方便的定义和实现自己的推荐算法。同时,Taste 不仅仅只适用于 Java 应用程序,它可以作为内部服务器的一个组件以 HTTP 和 Web Service 的形式向外界提供推荐的逻辑。
2、Taste工作原理
Taste 由以下五个主要的组件组成:
- DataModel:DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
- UserSimilarity 和 ItemSimilarity:UserSimilarity 用于定义两个用户间的相似度,它是基于协同过滤的推荐引擎的核心部分,可以用来计算用户的“邻居”,这里我们将与当前用户口味相似的用户称为他的邻居。ItemSimilarity 类似的,计算内容之间的相似度。
- UserNeighborhood:用于基于用户相似度的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的“邻居用户”的方式产生的。UserNeighborhood 定义了确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算得到的。
- Recommender:Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。程序中,为它提供一个 DataModel,它可以计算出对不同用户的推荐内容。实际应用中,主要使用它的实现类 GenericUserBasedRecommender 或者 GenericItemBasedRecommender,分别实现基于用户相似度的推荐引擎或者基于内容的推荐引擎。
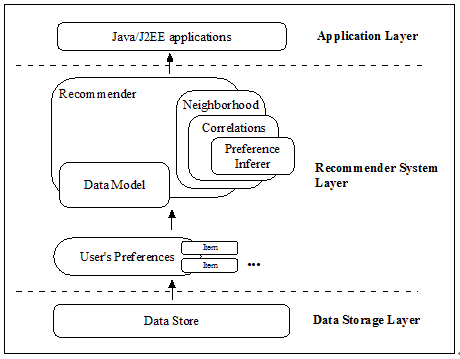
图1 Taste的主要组件图
3、构建电影推荐引擎
3.1 下载示例数据
本工程所用到的数据来源于此处 http://grouplens.org/datasets/movielens/
下载数据 “MovieLens 1M Dataset”
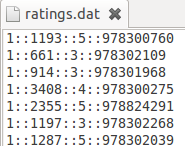
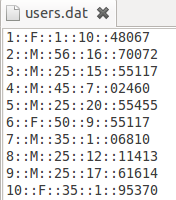
这个数据文件夹下有三个文件:movies.dat,ratings.dat和users.dat,数据形式如下三个图所示:
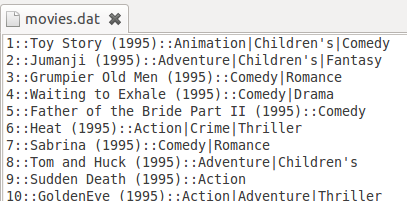
movies.dat的文件描述是 电影编号::电影名::电影类别
ratings.dat的文件描述是 用户编号::电影编号::电影评分::时间戳
users.dat的文件描述是 用户编号::性别::年龄::职业::Zip-code
这些文件包含来自6040个MovieLens用户在2000年对约3900部电影的1000209个匿名评分信息。
3.2推荐引擎实现
在本工程中,我实现了三种方式的推荐引擎:基于用户相似度的推荐引擎,基于内容相似度的推荐引擎,以及基于Slope One 的推荐引擎。在这些推荐引擎中,我分别使用了三种DataModel,即Database-based DataModel,File-based DataModel和In-memory DataModel。
a) 基于用户
public class MyUserBasedRecommender {
public List userBasedRecommender(long userID,int size) {
// step:1 构建模型 2 计算相似度 3 查找k紧邻 4 构造推荐引擎
List recommendations = null;
try {
DataModel model = MyDataModel.myDataModel();//构造数据模型,Database-based
UserSimilarity similarity = new PearsonCorrelationSimilarity(model);//用PearsonCorrelation 算法计算用户相似度
UserNeighborhood neighborhood = new NearestNUserNeighborhood(3, similarity, model);//计算用户的“邻居”,这里将与该用户最近距离为 3 的用户设置为该用户的“邻居”。
Recommender recommender = new CachingRecommender(new GenericUserBasedRecommender(model, neighborhood, similarity));//构造推荐引擎,采用 CachingRecommender 为 RecommendationItem 进行缓存
recommendations = recommender.recommend(userID, size);//得到推荐的结果,size是推荐接过的数目
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
return recommendations;
}
public static void main(String args[]) throws Exception {
}
}
Mahout 中提供了基本的相似度的计算,它们都实现了 UserSimilarity 这个接口,以实现用户相似度的计算,包括下面这些常用的:
•PearsonCorrelationSimilarity:基于皮尔逊相关系数计算相似度 (它表示两个数列对应数字一起增大或一起减小的可能性。是两个序列协方差与二者方差乘积的比值)
•EuclideanDistanceSimilarity:基于欧几里德距离计算相似度
•TanimotoCoefficientSimilarity:基于 Tanimoto 系数计算相似度
根据建立的相似度计算方法,找到邻居用户。这里找邻居用户的方法根据前面我们介绍的,也包括两种:“固定数量的邻居”和“相似度门槛邻居”计算方法,Mahout 提供对应的实现:
•NearestNUserNeighborhood:对每个用户取固定数量 N 的最近邻居
•ThresholdUserNeighborhood:对每个用户基于一定的限制,取落在相似度门限内的所有用户为邻居。
基于 DataModel,UserNeighborhood 和 UserSimilarity 构建 GenericUserBasedRecommender,从而实现基于用户的推荐策略。
b) 基于物品
public class MyItemBasedRecommender {
public List myItemBasedRecommender(long userID,int size){
List recommendations = null;
try {
DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//构造数据模型,File-based
ItemSimilarity similarity = new PearsonCorrelationSimilarity(model);//计算内容相似度
Recommender recommender = new GenericItemBasedRecommender(model, similarity);//构造推荐引擎
recommendations = recommender.recommend(userID, size);//得到推荐接过
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
return recommendations;
}
}
在这个推荐引擎中,使用的是File-based Datamodel,数据文件格式如下图所示:
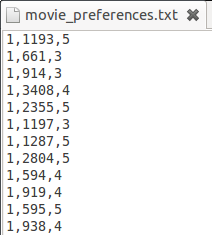
每一行都是一个简单的三元组< 用户 ID, 物品 ID, 用户偏好 >。
c) 基于Slop One的推荐引擎
基于用户和基于内容是最常用最容易理解的两种推荐策略,但在大数据量时,它们的计算量会很大,从而导致推荐效率较差。因此 Mahout 还提供了一种更加轻量级的 CF 推荐策略:Slope One。
Slope One 是有 Daniel Lemire 和 Anna Maclachlan 在 2005 年提出的一种对基于评分的协同过滤推荐引擎的改进方法,下面简单介绍一下它的基本思想。
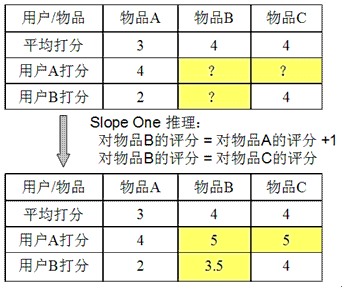
假设系统对于物品 A,物品 B 和物品 C 的平均评分分别是 3,4 和 4。基于 Slope One 的方法会得到以下规律:
•用户对物品 B 的评分 = 用户对物品 A 的评分 + 1
•用户对物品 B 的评分 = 用户对物品 C 的评分
基于以上的规律,我们可以对用户 A 和用户 B 的打分进行预测:
•对用户 A,他给物品 A 打分 4,那么我们可以推测他对物品 B 的评分是 5,对物品 C 的打分也是 5。
•对用户 B,他给物品 A 打分 2,给物品 C 打分 4,根据第一条规律,我们可以推断他对物品 B 的评分是 3;而根据第二条规律,推断出评分是 4。当出现冲突时,我们可以对各种规则得到的推断进行就平均,所以给出的推断是 3.5。
这就是 Slope One 推荐的基本原理,它将用户的评分之间的关系看作简单的线性关系:
Y = mX + b;
当 m = 1 时就是 Slope One,也就是我们刚刚展示的例子。
public class MySlopeOneRecommender {
public List mySlopeOneRecommender(long userID,int size){
List recommendations = null;
try {
DataModel model = new FileDataModel(new File("/home/huhui/movie_preferences.txt"));//构造数据模型
Recommender recommender = new CachingRecommender(new SlopeOneRecommender(model));//构造推荐引擎
recommendations = recommender.recommend(userID, size);//得到推荐结果
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
return recommendations;
}
}
d) 对数据模型的优化——In-memory DataModel
原文 http://blog.csdn.net/huhui_cs/article/details/8596388