

Flume是Cloudera提供的一个分布式、可靠、高可用的海量日志采集、聚合和传输的日志收集系统。Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源收集数据。
Flume NG采用的是三层架构:Agent层,Collector层和Store层,每一层均可水平拓展。其中Agent包含Source,Channel和Sink,三者组建了一个Agent。三者的职责如下所示:
- Source:用来收集数据源到Channel中, 数据源包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http等
- Channel:中转临时存储,保存所有Source组件信息,channel中的数据只有在sink发送成功之后才会被删除。
- Sink:用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr。
在整个数据传输过程中,流动的是event。事务保证是在event级别。 Flume支持用户建立多级流,也就是说,多个agent可以协同工作,支持扇入(fan-in)、扇出(fan-out)。
来个比喻:有一个池子,它一头进水,另一头出水,进水口可以配置各种管子,出水口也可以配置各种管子,可以有多个进水口、多个出水口。水术语称为Event,进水口术语称为Source、出水口术语成为Sink、池子术语成为Channel,Source+Channel+Sink,术语称为Agent。如果有需要,还可以把多个Agent连起来。
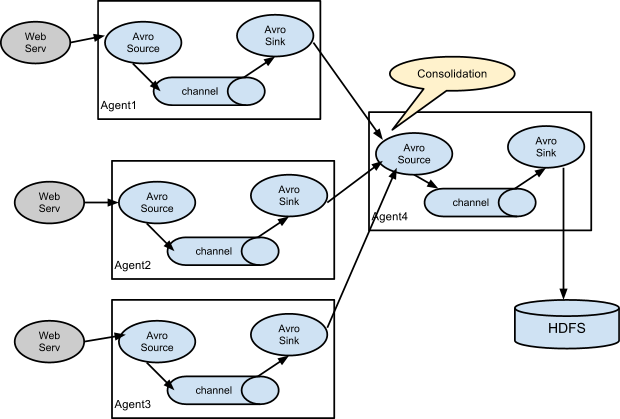
Flume简单处理示意图

多 agent 汇聚写入 HDFS
二、Flume安装配置
1 需要安装jdk
2 从官网下载Flume 二进制安装包,解压即可使用 tar -xvf apache-flume-1.6.0-bin.tar.gz
#验证 flume
# flume-ng version
配置
source 使用 necat 类型,sink 采用 file_roll 类型, 从监听端口获取数据,保存到本地文件。 拷贝配置模板:
cp conf/flume-conf.properties.template conf/agent.conf
编辑配置如下:
# The configuration file needs to define the sources, # the channels and the sinks. # Sources, channels and sinks are defined per agent, # in this case called agent a1.sources = r1 a1.channels = c1 a1.sinks = s1 # For each one of the sources, the type is defined a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 8888 # The channel can be defined as follows. a1.sources.r1.channels = c1 # Each sinks type must be defined a1.sinks.s1.type = file_roll a1.sinks.s1.sink.directory = /tmp/log/flume #Specify the channel the sink should use a1.sinks.s1.channel = c1 # Each channels type is defined. a1.channels.c1.type = memory # Other config values specific to each type of channel(sink or source) # can be defined as well # In this case, it specifies the capacity of the memory channel a1.channels.c1.capacity = 100
#启动agent
flume-ng agent -c conf -f conf/agent.conf -n a1 -Dflume.root.logger=INFO,console
#命令参数说明
-c conf 指定配置目录为conf
-f conf/example.conf 指定配置文件为conf/agent.conf
-n a1 指定agent名字为a1,需要与agent.conf中的一致
-Dflume.root.logger=INFO,console 指定DEBUF模式在console输出INFO信息
3.发送数据
telnet localhost 8888 #输入 hello world! hello Flume!
4.查看数据文件 查看 /tmp/log/flume 目录文件:
cat /tmp/log/flume/1447671188760-2 hello world! hello Flume!
与Kafka 集成
Flume 可以灵活地与Kafka 集成,Flume侧重数据收集,Kafka侧重数据分发。 Flume可配置source为Kafka,也可配置sink 为Kafka。 配置sink为kafka例子如下
agent.sinks.s1.type = org.apache.flume.sink.kafka.KafkaSink agent.sinks.s1.topic = mytopic agent.sinks.s1.brokerList = localhost:9092 agent.sinks.s1.requiredAcks = 1 agent.sinks.s1.batchSize = 20 agent.sinks.s1.channel = c1
Flume 收集的数据经由Kafka分发到其它大数据平台进一步处理。